
Возможно, некоторые знают, что я разработал алгоритм, а М. Шардин реализовал его в виде скрипта, который позволяет отбирать акции на основе фундаментального анализа компаний-эмитентов. Вот общее описание алгоритма:
https://gregbar.livejournal.com/922938.html
Сегодня решил проверить, каковы будут результаты реализации на его основе моей любимой Стратегии "скользящего среднего". Ведь бэктестинг этого алгоритма был ранее проведён на 25 годах: с начала 1996 по конец 2020 годов. Там я запускал отбор акций 1 января каждого года, алгоритм отбирал акции, а мы проверяли после этого, к каким результатам приведёт такой отбор за 1,2,3,4,5 или 6 лет владения. Там получились любопытные результаты, которые я описал https://gregbar.livejournal.com/920158.html Сейчас нетрудно на основе этого алгоритма и с учётом полученных результатов бэктестинга проверить мою любимую Стратегию инвестирования.
Задача ставится так: Инвестор 1 января 1996 года покупает рекомендованный алгоритмом список акций, вкладывая в каждую позицию одинаковую сумму. Всего на, скажем, 20 тысяч долларов. Через год, 1 января 1997, инвестор добавляет к своим инвестициям ещё 20 тысяч долларов. Чтобы понять, что ему покупать, он опять запускает программу отбора акций, и алгоритм опять выдаёт ему список акций, которые рекомендованы ему к покупке на данный момент. Инвестор на свои новые 20 тысяч долларов покупает рекомендованные акции, вкладывая в каждую позицию равную по величине сумму. Теперь в его портфеле имеется уже два "портфельчика" разного возраста: один прошлогодний, а второй совсем свежий. Инвестор не смешивает эти "портфельчики", он ведёт учёт по ним отдельно.
Итак, у него есть два "портфельчика" разного возраста. То же самое он повторяет 1 января 1998, 1999, 2000 и 2001 годов. Теперь у него в портфеле уже 6 "портфельчиков" разного срока свежести. Самый старый "портфельчик" у него уже шестой год безо всяких изменений хранится. Инвестор за это время уже инвестировал приличную сумму - 120 тысяч долларов. Но это и всё. Больше ему вкладывать не придётся. Потому что 1 января 2002 года Инвестор продаёт свой самый старый (шестилетний) портфельчик, а на вырученные деньги покупает рекомендованный алгоритмом "свежий" набор акций. Точно так же, как и раньше. И теперь Инвестор наступление каждого Нового года отмечает продажей своего самого старого (шестилетнего) портфеля, покупая взамен рекомендуемые алгоритмом акции. Формирует таким образом новый, свежий "портфельчик" данного года выпуска. Таким образом ведёт себя наш инвестор долго, 25 лет в общей сложности, до конца 2020 года.
Как видим, Стратегия довольно тупая, любой справится. И времени тратится минимум: прогнал программу, получил список, продал старое, купил новое. Всё! Целый год свободен. Но каковы же результаты? Вот они (кликабельно):
(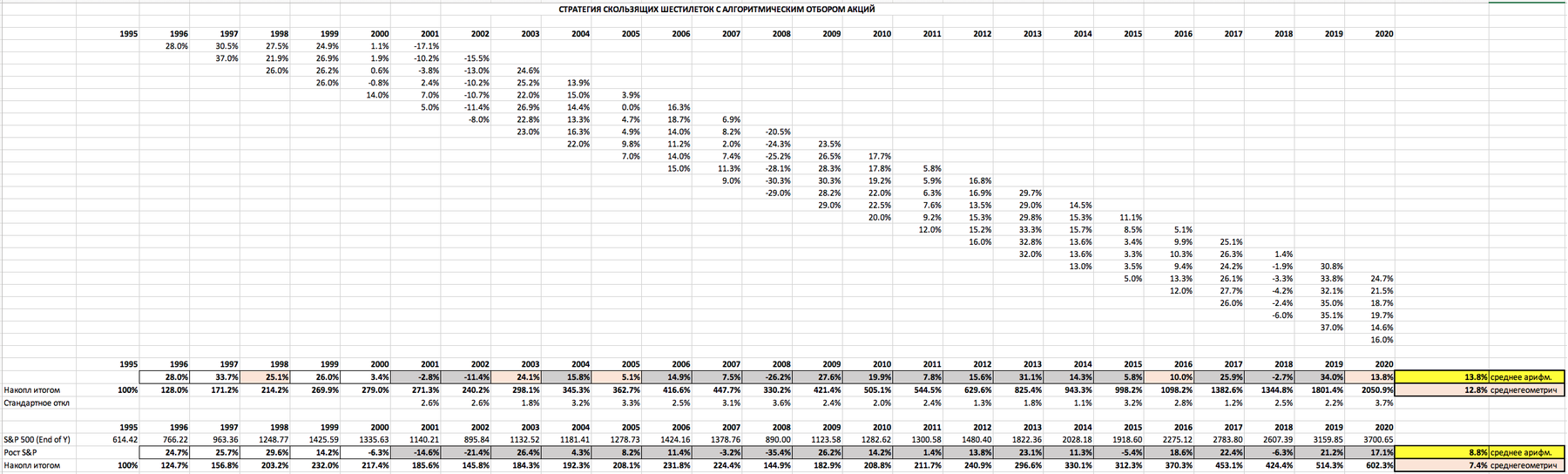
Внизу две группы строк, это результаты для данной стратегии в сравнении с данными рыночного индекса. Как видим, за 25 лет Инвестор увеличил свои активы в 20 раз. А те, кто инвестировал в S&P 500, увеличили свои активы только в 6 раз (тоже, конечно, хороший результат). Это произошло потому, что в течение этой 25-летки у Инвестора, который действовал по описанной Стратегии, среднегодовая номинальная доходность составляла 13,8% годовых, а у S&P 500 - 8,8%. Среднегеометрическая номинальная доходность по Стратегии составила 12,8% годовых, а у S&P 500 - 7,4%.
Более наглядно это можно увидеть на графике:
(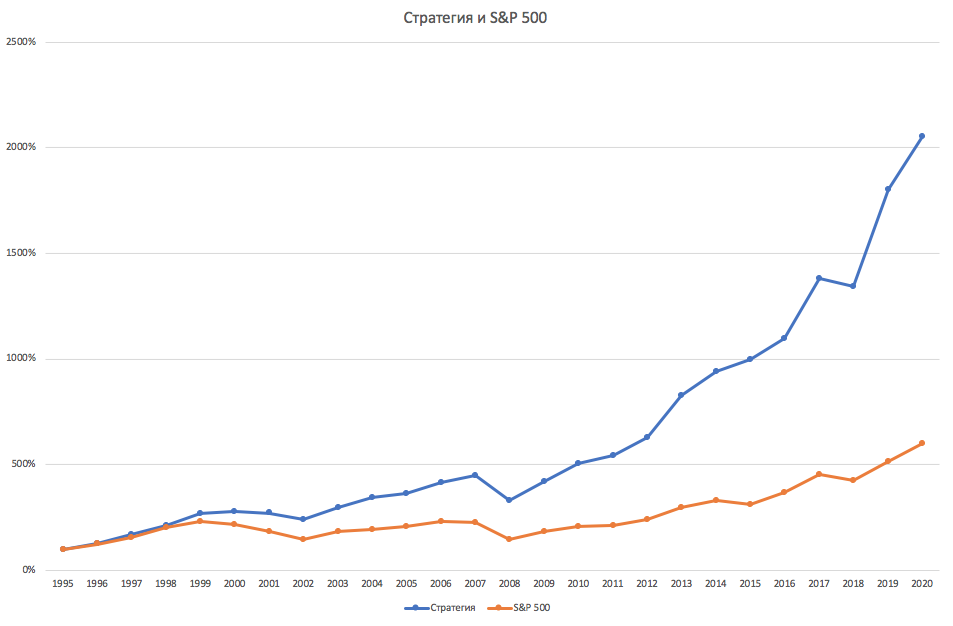
При этом волатильность Стратегии не превышает волатильность S&P 500, даже немного меньше. Стандартное отклонение составляет у Стратегии 14,7% против 16,7% у S&P. Поэтому Шарп у Стратегии почти вдвое выше рыночного: 0,84 против 0,44 у S&P. Максимальная просадка у Стратегии = -26,2%, у S&P 500 = -35,4% (обе в 2008 году). При этом корреляция результатов Стратегии и S&P 500 очень высокая: 0,94. Что и так видно на графике.
Если же сравнивать реальную доходность, то можно грубо оценить инфляцию в США примерно в 3% годовых. Тогда реальная средняя доходность Стратегии составляет 9,8% против 4,4% у индекса. Разница более, чем вдвое.
Ну и в конце - про российского инвестора. Курс доллара к рублю 2 января 1996 года был 5,28 рублей за доллар, а 1 января 2021 года он составлял 73,61 рубля за доллар. Среднегодовой рост (Compaund) составил 11,1%. Тогда номинальный рост в рублях для такой Стратегии даёт инвестору доходность 12,8%+11,1%=23,9%. Это, разумеется, слишком большой рост. Он связан со скачком курса доллара в России в 1998 году. Вряд ли он будет таким в следующие 25 лет. Но даже если взять очень осторожные 5% годовых средней девальвации рубля к доллару, то рублёвая доходность Стратегии составит 17,8% годовых. Что тоже смотрится неплохо.
Примечание. В качестве бенчмарка взят индекс S&P 500. Это связано с тем, что алгоритм отбрасывает фирмы с капитализацией менее 4 миллиардов долларов. А исследование проводилось исключительно на рынке США. Поэтому S&P 500, по моему мнению, адекватно отражает рынок в данном случае.

Спасибо всем за дискуссию. Особо тем, кто сделал замечания. Понял, что должен кое-что пояснить.
Исходные допущения я не описал явно. Это плохо. Они таковы:
я не лезу глубоко в анализ финансовых таблиц компаний, которые беру из базы. Понимаю, что там возможны ошибки. Я исхожу из того, что их немного и при формировании портфеля из примерно 30 бумаг они не повлияют существенно на общий результат. Это утверждение ничем не доказывается, это гипотеза.
другая гипотеза состоит в том, что мы, анализируя прошлое какой-то компании, можем с определённой вероятностью расчитывать, что и в будущем (более или менее длительном) будем наблюдать сходные результаты её деятельности. Это гипотеза об относительно медленных изменениях бизнеса. Эта гипотеза идёт ещё со времён Грэма.
и я предполагаю также, что если у компании в будущем накопятся серьёзные проблемы, то это отразится в экономических показателях её работы, и алгоритм просто отбракует такую фирму в будущем. Но это тоже лишь гипотеза.
в отличие от наиболее распространённого подхода, я включаю в портфель все бумаги в равных объёмах (в деньгах), а не пропорционально капитализации компании. Это связано с тем, что полученный портфель никоим образом не претендует на то, чтобы отобразить рынок. А какие бумаги "выстрелят" я не имею никакого понятия.
Мне в некоторых комментах делали, справедливые в какой-то мере, замечания из серии "через любые N+1 точку всегда можно провести график полинома N-й степени так, что он точно пройдёт по всем точкам". Другими словами, если параметров настройки модели много, то можно так их подобрать, что на 25 годах мы будем получать замечательные результаты, но никакой прогностической силы эта модель иметь не будет.
Теоретически - да. Но тогда мне при настройке параметров надо было бы двигать их значения так, чтобы выбирались именно лучшие для данного периода результаты и так делать 25 раз для всех точек старта и следить за тем, что если в этом году получилось хорошо. то надо всё время проверять, что при этом не испортились старые года в смысле настройки. И ещё надо смотреть при этом, чтобы в каждый год при этом все 6 портфельчиков давали хорошие результаты в каждый конкретный год. Короче, я ни только не делал ничего подобного, но и даже не представляю, как можно подступиться к задаче такой невиданной размерности. Я исходил в выборе параметров из обычных экономических соображений, которые содержатся в подходе фундаментального анализа. Например, что высокая маржа прибыли - это хорошо, а низкая плохо. Но где поставить ограничение? Я опирался на статистику средних значений мультипликаторов по рынку США, имеющуюся в литературе, и на собственный опыт, если не находил опубликованные цифры.
Впрочем, здесь ответ на вопрос будет дан практикой. Если практическое использование этой стратегии даст в будущем хорошие результаты, то это будет (косвенным, только косвенным, конечно) доказательством наличия прогностической силы у такого метода.
Гораздо больше мне нравится проверка того, насколько эти результаты устойчивы, методом "по Силаеву": насколько всякие изменения существенно или не существенно меняют результат. Они оказались устойчивы, я проверял. Впрочем, можно убедиться в этом даже, например, по приведённой в тексте таблице. Так, в 2002 году все 6 портфельчиков разной "свежести", которые имеются у инвестора в своём большом портфеле, показывают довольно компактно расположенные цифры убытков, от -8% до -11,4%, в то время, как рыночный индекс показал убыток -21,4%. При этом важно отметить, что состав бумаг в этих 6 портфелях очень разный, не похожий один на другой. То же самое вы можете проверить и за другие годы. Это говорит о том (опять же только косвенно), что алгоритм работает, он формирует портфели разные по составу входящих в них акций, но дающие похожие результаты в смысле доходности/убыточности. То есть, можно сделать вывод, что алгоритм выбирает в целом скорее хорошие компании, чем плохие. Об этом же говорят и ещё некоторые обстоятельства. Не буду их упоминать, чтобы не затягивать безмерно эту и так затянувшуюся реплику.
И, наконец, надо помнить, что этот алгоритм не такой уж винер-винер: из каждых 5 лет в среднем один год оказывается неудачным, проигрывает индексу.
Ещё раз, спасибо всем за обсуждение.
Так а что за Стратегия в итоге? Какие в ней мультипликаторы для чего используются, какие корректировки ошибок бух. учета (например, списание R&D в расходы) при расчете этих мультипликаторов? Или хотя бы на что больше смотрите - стоимость компании, денежные потоки, уровень долга?
Я прочитал пост и глянул в ЖЖ ссылку, но ощущение осталось будто мне чудо-алгоритм на комоне продают. 🙂
Ещё график бы показать за вычетом НДФЛ с учетом продажи всего портфеля каждый год, всё-таки у buy & hold бенчмарка эта издержка есть только раз в самом конце, а тут мы каждый год продаем и перевкладываем уменьшенную на 13% прибыль получается - тогда компаундить результаты по стратегии за весь период с 1995 года некорректно.
@Gregbar Григорий, очень впечатляющие результаты!
Скажите, а сколько компаний в среднем получается в портфеле? Пропорции, насколько я помню, у вас распределяются равными долями на все компании?
Спасибо за интересный пост!
Исходя из описания алгоритма в ЖЖ (https://gregbar.livejournal.com/922938.html), вы исключили из рассмотрения следующие отрасли:
Все эти отрасли за рассматриваемый период показали доходность ниже S&P500. Может быть тогда доходность Стратегии обусловлена исключением этих отраслей, а не фильтрами, через которые проходят оставшиеся компании для попадания в портфель?
Было бы интересно увидеть динамику акций, которые не прошли критерии отбора. Возможно, что они выросли еще сильнее :)
Посмотрел ещё и пост в жж. Не понял, за какой период использованы данные для обучения модели, и за какой- для проверки? Вообще то это должны быть разные периоды, и, в идеале, 3.
Пример: с 85 по 2000 используете данные для подобора весов (граничных значений мультипликаторов) и сам выбор фич (мультипликаторов). Качество такого выбора проверяете на периоде 2001-2010. А потом, выбрав модель с максимальным качеством, проверяете её на третьем, независимом периоде. В моем примере 2011-2021.
Если подобрать весов для скрининга и рейтинга шёл не по такому алгоритму, если вы оценивали работу модели на тех же данных, на которых её учли- у вас переобученная модель.